
[TOC]
实验二:知识图谱认知进阶
实验目的
- 掌握大数据文件的处理方法
- 掌握大数据文件导入到图数据库的相关知识
- 掌握大数据文件导入到图数据库的相关操作
实验原理
数据清洗(Data Cleaning)
处理缺失值(Handing Missing values)
现实世界的数据通常有很多缺失值。缺失值的原因可能是数据损坏或未能记录数据。在数据集的预处理过程中,缺失数据的处理非常重要,因为许多机器学习算法不支持缺失值。
大致有7种处理数据集中缺失值的方法:
- 删除缺少值的行;
- 为连续变量插补缺失值;
- 估算分类变量的缺少值;
- 其他插补方法;
- 使用支持缺失值的算法;
- 缺失值的预测;
- 使用深度学习库进行插补。
删除缺少值的行
可以通过删除具有空值的行或列来处理缺失值。如果列有超过一半的行为空,则可以删除整个列。也可以删除一个或多个列值为 null 的行。
优点:
- 通过删除所有缺失值进行训练的模型会创建一个稳健的模型。
缺点:
- 大量信息丢失。
- 如果缺失值的百分比与完整数据集相比过多,则效果不佳。
用均值/中值估算缺失值
数据集中具有数字连续值的列可以替换为列中剩余值的平均值、中位数或众数。与早期的方法相比,这种方法可以防止数据丢失。替换上述两个近似值(均值、中值)是一种处理缺失值的统计方法。
优点:
- 防止导致行或列删除的数据丢失;
- 适用于小型数据集并且易于实现。
缺点:
- 仅适用于数值连续变量;
- 可能导致数据泄露;
- 不要考虑特征之间的协方差。
分类列的插补方法
当缺失值来自分类列(字符串或数字)时,缺失值可以替换为最常见的类别。如果缺失值的数量非常大,则可以将其替换为新类别。
优点:
- 防止导致行或列删除的数据丢失
- 适用于小型数据集并且易于实现。
- 通过添加唯一类别来消除数据丢失
缺点:
- 仅适用于分类变量。
- 编码时向模型添加新特征,这可能会导致性能不佳
其他插补方法
根据数据或数据类型的性质,其他一些插补方法可能更适合于插补缺失值。
例如,对于具有纵向行为的数据变量,使用最后一个有效观察值来填充缺失值可能是有意义的。这被称为最后一次观察结转 (LOCF) 方法。
对于时间序列数据集变量,在时间戳之前和之后使用变量的插值来获取缺失值是有意义的。
使用支持缺失值的算法
所有机器学习算法都不支持缺失值,但一些机器学习算法对数据集中的缺失值具有鲁棒性。当缺少值时,k-NN 算法可以忽略距离度量中的列。朴素贝叶斯还可以在进行预测时支持缺失值。当数据集包含空值或缺失值时,可以使用这些算法。
Python 中朴素贝叶斯和 k-Nearest Neighbors 的 sklearn 实现不支持缺失值的存在。
可以在这里使用的另一种算法是 RandomForest,它适用于非线性和分类数据。它适应考虑高方差或偏差的数据结构,在大型数据集上产生更好的结果。
优点:
- 无需处理每列中的缺失值,因为 ML 算法将有效地处理它们。
缺点:
- scikit-learn 库中没有这些 ML 算法的实现。
缺失值的预测
在早期处理缺失值的方法中,我们没有利用包含缺失值的变量与其他变量的相关性优势。使用没有空值的其他特征可用于预测缺失值。
回归或分类模型可用于根据具有缺失值的特征的性质(分类或连续)来预测缺失值。
优点:
- 比以前的方法提供更好的结果
- 考虑缺失值列与其他列之间的协方差。
缺点:
- 仅被视为真实值的代理
使用深度学习库进行插补
这种方法非常适用于分类、连续和非数字特征。Datawig 是一个库,它使用深度神经网络来学习 ML 模型,以估算数据报中的缺失值。
Datawig 可以采用数据框并为具有缺失值的每一列拟合一个插补模型,并将所有其他列作为输入。
优点:
- 与其他方法相比相当准确。
- 它支持 CPU 和 GPU。
缺点:
- 使用大型数据集可能会很慢。
缩放与归一化(Scaling and Normalization)
数据缩放
在统计学中的意思是,通过一定的数学变换方式,将原始数据按照一定的比例进行转换,将数据放到一个小的特定区间内,比如0~1或者-1~1。目的是消除不同样本之间特性、数量级等特征属性的差异,转化为一个无量纲的相对数值,结果的各个样本特征量数值都处于同一数量级上。
如何进行数据缩放
指标一致化
目的是解决数据性质不同的问题,也就是说涉及到多个不同的统计量时,有的指标数值越大越符合预期(如:药物治疗后的生存率),也要一些指标数值越小越符合预期(如:死亡率)。可以看出这两种数据的”方向”是不同的。这时,如果要综合考量两种数据,就要先统一数据方向,一般方法有两种:
- 对原始数据取倒数=》倒数一致(但是这样会改变原始数据的分散程度,间接放大或缩小数据的实际差异)
- 定义不同指标中数值上限,然后依次减去每个指标中的原始数据(它不会改变数据的分散程度,相比于倒数法结果更加稳定)
无量纲化
这个是我们经常用到的,目的是解决数据之间的可比性问题,比如有的指标/样本中数据范围在1-100,另一个指标/样本中数据在1-10000,这个范围就是”量纲”。标准化要做的,就是去掉这个的影响,真正突出数据的差别,有点绝对值变为相对值的感觉。可以用的方法有:
-
极差法:它是最简单处理量纲问题的方法,它是将数据集中某一列数值缩放到0和1之间,又称”归一化 Normalization”。 它的计算方法是:
(观测值-最小值)/极差,极差=最大值-最小值 因此无论数值是正是负,那么结果范围都变到了0~1 但有一个问题:如果再引入数据,那么可能整个计算结果需要更改 -
log函数标准化
它也属于归一化的范畴 适用于原始数据大于等于1的情况,对指标中的每一个观测值都取以10为底的log值,然后除以这个指标最大值的log10,即
log10(X)/log10(MAX) -
z-score法:想必经常会听人说使用这个方法进行标准化,听着很难懂,但是计算方法不难,它又叫”(标准差)标准化 Standardization”,就是将某一列数值按比例缩放成均值为0,方差为1的形式。 适用于:指标中的数据最大最小值未知,或者有离群点时,用极差法可能会带来较大的误差。 z-score是这么做的:先计算均值(mean)和标准差(sd),然后用每个观测值减去均值,再除以标准差,即:
(x-mean)/sd得到的结果数据变成了正态分布,结果范围在-1~1。
标准化与归一化
标准化、归一化这两个概念总是被混用,以至于有时以为这是同一个概念,既然容易混淆就一定存在共性:它们都是对某个特征(或者说某一列/某个样本)的数据进行缩放(scaling)。
二者差异:归一化Normalization受离群点影响大;标准化Standardization是重新创建一个新的数据分布,因此受离群点影响小
- 如果数据集小而稳定,可以选择归一化
- 如果数据集中含有噪声和异常值,可以选择标准化,标准化更加适合嘈杂的大数据集。
字符编码(Character Encoding)
什么是编码
字符编码是一组特定的规则,用于将原始二进制字节字符串(看起来像:01101000001101001)映射到构成人类可读文本的字符(像“hi”)。有许多不同的编码,如果你试图用不同的编码来阅读文本,你最终会得到被称为“mojibake”的混乱文本(如mo gee bah kay所说)。以下是mojibake的一个例子:
æ-‡-å-Œ-ã??
您也可能最终得到一个“未知”字符。当用于读取字节字符串的编码中的特定字节和字符之间没有映射时,会打印出如下内容:
����������
如今,字符编码不匹配的情况比以前少了,但这肯定仍然是一个问题。有很多不同的字符编码,但您需要了解的主要字符编码是UTF-8。
UTF-8是标准的文本编码。所有Python代码都是UTF-8,理想情况下,您的所有数据也应该是UTF-8。当事情不在UTF-8中时,你就会遇到麻烦。
在Python 2中很难处理编码,但是,在Python 3中它要简单得多。在Python 3中处理文本时,您会遇到两种主要的数据类型。一个是字符串,默认情况下是文本。
读入有编码问题的文件
您将遇到的大多数文件可能都是用UTF-8编码的。这是Python在默认情况下所期望的,因此大多数情况下不会遇到问题。但是,有时会出现如下错误:
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
/tmp/ipykernel_19/3982885289.py in <module>
1 # try to read in a file not in UTF-8............
请注意,当我们尝试将UTF-8字节作为ASCII进行解码时,我们得到了相同的UnicodeDecodeError!这告诉我们这个文件实际上不是UTF-8。我们不知道它实际上是什么编码。解决这个问题的一种方法是尝试并测试一组不同的字符编码,看看其中是否有一种可以工作。不过,更好的方法是使用chardet模块尝试并自动猜测正确的编码是什么。这并不能百分之百保证是正确的,但它通常比仅仅猜测要快。
我们只看一下文件的前10000字节。这通常足以很好地猜测编码是什么,并且比查看整个文件快得多。(尤其是对于大文件,这可能会非常慢。)查看文件的第一部分的另一个原因是,通过查看错误消息,我们可以看到第一个问题是第11个字符。因此,我们可能只需要查看文件的第一小段,就可以了解发生了什么。
如果编码chardet猜测不正确怎么办?由于chardet基本上只是一个猜测者,有时它会猜测错误的编码。您可以尝试的一件事是查看文件的多多少少,看看是否得到不同的结果,然后尝试。
使用 UTF-8 保存文件
最后,一旦您解决了将文件导入UTF-8的所有问题,您可能希望保持这种方式。最简单的方法是使用UTF-8编码保存文件。好消息是,由于UTF-8是Python中的标准编码,因此在保存文件时,默认情况下会将其保存为UTF-8;
filename.to_csv(filepath)
py2neo
py2neo 的安装
直接通过 pip 下载即可;
pip install py2neo
连接Neo4j
from py2neo import Graph,Node,Relationship
graph = Graph("http://localhost:7474",auth=("neo4j","password"))
def __init__(self, profile=None, name=None, **settings):
self.service = GraphService(profile, **settings)
self.__name__ = name
self.schema = Schema(self)
self._procedures = ProcedureLibrary(self)
Node Object
Node 初始化:
def __init__(self, *labels, **properties):
self._remote_labels = frozenset()
self._labels = set(labels)
Entity.__init__(self, (self,), properties)
Node 是保存在 Neo4j 里面的数据存储单元,在创建好 node 以后,我们可以有许多操作:
#获取key对应的property
x=node[key]
#设置key键对应的value,如果value是None就移除这个property
node[key] = value
#也可以专门删除某个property
del node[key]
#返回node里面property的个数
len(node)
#返回所以和这个节点有关的label
labels=node.labels
#删除某个label
node.labels.remove(labelname)
#将node的所有property以dictionary的形式返回
dict(node)
Relationship Object
Relationship 初始化:
def __init__(self, *nodes, **properties):
n = []
for value in nodes:
if value is None:
n.append(None)
elif isinstance(value, string_types):
n.append(value)
elif isinstance(value, Node):
n.append(value)
else:
raise TypeError("Unknown node type for %r" % value)
num_args = len(n)
if num_args == 0:
raise TypeError("Relationships must specify at least one endpoint")
elif num_args == 1:
# Relationship(a)
n = (n[0], n[0])
elif num_args == 2:
if n[1] is None or isinstance(n[1], string_types):
# Relationship(a, "TO")
self.__class__ = Relationship.type(n[1])
n = (n[0], n[0])
else:
# Relationship(a, b)
n = (n[0], n[1])
elif num_args == 3:
# Relationship(a, "TO", b)
self.__class__ = Relationship.type(n[1])
n = (n[0], n[2])
else:
raise TypeError("Hyperedges not supported")
Entity.__init__(self, (n[0], self, n[1]), properties)
相关的操作:
#创建Relationship
Relationship`(*start_node*, *type*, *end_node*, ***properties*)
#返回Relationship的property
Relationship[key]
#删除某个property
del Relationship[key]
#将relationship的所有property以dictionary的形式返回
Subgraphs(子图)
子图是节点和关系不可变的集合,我们可以通过set operator来结合,参数可以是独立的node或relationships。
subgraph | other | ... 结合这些subgraphs
subgraph & other & ... 相交这些subgraphs
subgraph - other - ... 不同关系
#比如我们前面创建的ab关系
s = ab | ac
Query 查询
最新的v4版本中,对node的查询,已经移除原有的find(),可以在nodes中调用match来找点;
graph.nodes.match(self, *labels, **properties): 找到所有的nodes,
或者使用 py2neo.matching 包里面的NodeMatcher(graph)函数构建个matcher再查询(其实上面的方法就调用的这个东西);
首先创建Matcher来执行查询,它会返回一个Match类型的数据,可以继续使用where(),first(),order_by等操作,可以用list强制转换。
graph = Graph()
matcher = NodeMatcher(graph)
matcher.match("Person", name="Keanu Reeves").first()
#结果 (_224:Person {born:1964,name:"Keanu Reeves"})
# where里面使用_指向当前node
list(matcher.match("Person").where("_.name =~ 'K.*'"))
如果要查询 Relationship,直接在 graph 中调用:
graph.match(nodes=None, r_type=None, limit=None) 找到所有的relationships
Update(更新)
更新先要找出Nodes,再使用事务的 push 更新:
from py2neo import Graph, NodeMatcher, Subgraph
tx = graph.begin()
# 找到你要找的Nodes
matcher = NodeMatcher(graph)
nodes = matcher.match("User")
# 将返回的“Match”类转成list
new_nodes = list(nodes)
# 添加你要修改的东西
for node in new_nodes:
node['tag'] = node['tag'].split(',')
# 里面是Node的list可以作为Subgraph的参数
sub = Subgraph(nodes=new_nodes)
# 调用push更新
tx.push(sub)
tx.commit()
批处理
对于大量的插入一般是很费时的,首先我们可以使用事务,加快一定速度,而插入的方法一样重要,我们很多时候是遍历一个文件然后生成图,例子中我们生成每个Node后,先把他们放入一个List中,再变为Subgraph实例,然后再create(),耗时比一条条插入至少快10倍以上。
tx = graph.begin()
nodes=[]
for line in lineLists:
oneNode = Node()
........
#这里的循环,一般是把文件的数据存入node中
nodes.append(oneNode)
nodes=neo.Subgraph(nodes)
tx.create(nodes)
tx.commit()
前面我们说了关系的创建,如果在node存进去后,再通过py2neo层面的“查找node,create关系”这样的效率是很低的,时间主要花在通过”reference Id“去一个个去查找对应的node,然后再和这个node建立关系,这里强烈推荐使用原生语句,效率不是一般的高。
#假定我们已经把两种node存进去了,label分别是Post和User,现在需要在他们间建立某关系
graph.run("MATCH (p:Post),(u:User) \
WHERE p.OwnerUserId = u.Id \
CREATE (u)-[:Own]->(p)")
数据导入(Data Import)
LOAD & CSV
CSV格式的数据是文本数据,数据之间用英文逗号隔开。 支持的数据类型:仅CSV;
- 好处:操作简单;
- 坏处:运行时间长。
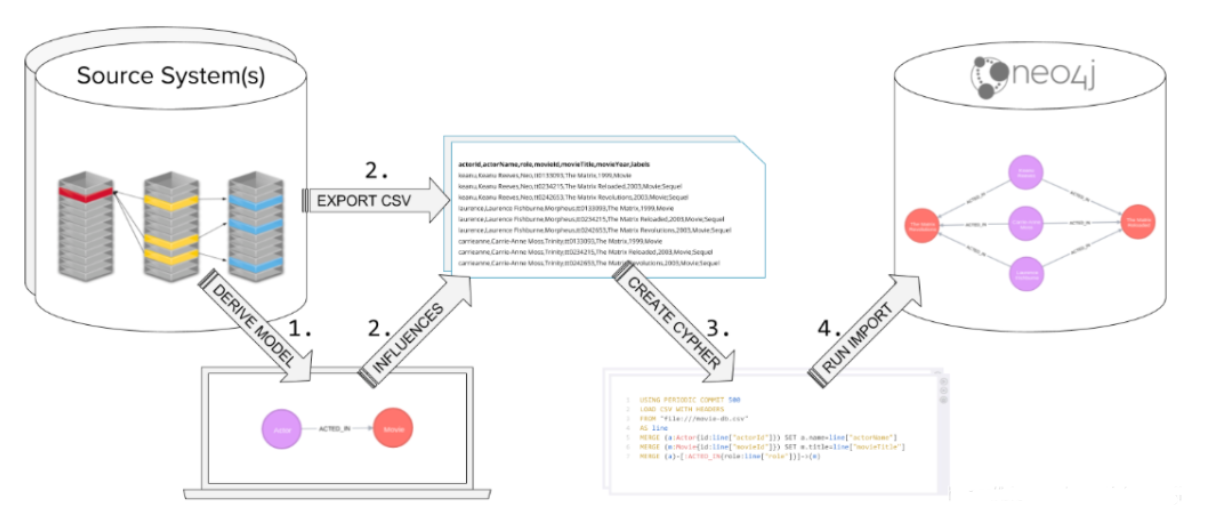
关键步骤就是:先生成CSV文件,然后用Cypher语句“LOAD CSV”将数据导入到Neo4j数据库中。 这种方式是最简单的导入数据到neo4j的方式,也是广泛使用来导入原始数据。
使用LOAD CSV 要求:
- CSV文件已经备好;
- Neo4j Browser或Cypher-shell已打开,Neo4j DBMS在本地运行,或Aura,或Sandbox;
- 可选(不是必须):在Neo4j集群上;
- 如果大于100K行数据,则需要特殊处理。
用 Cypher 加载数据的步骤如下:
- CSV文件组织结构;
- 规范化数据;
- 确保ID唯一;
- 确保CSV中的数据是干净的;
- 执行Cypher代码来检查数据;
- 确定数据是否需要转化;
- 确保有必要的数据约束;
- 确定加载数据量的大小;
- 执行Cypher代码来加载数据;
- 为图数据添加索引。
CSV文件包括header和data两部分,当数据量较大且有多个files时,建议将header与data分离开。
数据需要检查的条项如下:
- 检查header与对应数据列是否匹配
- 数据参照是否正确
- 空值是用“”还是NULL
- 数据格式,UTF-8
- 有些字段有尾随空格吗?
- 字段是否包含二进制零
- 了解列表是如何形成的,默认是冒号(:)作为分隔符
- 逗号(:)是分隔符吗?
使用APOC数据
支持数据格式:CSV,XML,GraphXML,JSON 使用APOC导入数据的要求:
- CSV,XML,或JSON文件;
- Neo4j Browser或Cypher-shell已打开,Neo4j DBMS在本地运行,或Aura,或Sandbox;
- 可选(不是必须):在Neo4j集群上;
- 对导入数据集大小没有限制。
使用编程语言导入数据

编程语言-驱动-Neo4j的方式来导入数据。 使用驱动导入数据的要求:
- Neo4j Browser或Cypher-shell已打开,Neo4j DBMS在本地运行,或Aura,或Sandbox;
- 可选(不是必须):在Neo4j集群上;
- 运行中的RDBMS服务器;
- 负责事务作用域的应用程序,即编程语言;
- 对导入数据量大小无限制;
- 支持Java、Python、Javascript、C#等,仅有Java和C#支持异步。
使用 neo4j-admin 工具导入数据
支持的数据格式:仅CSV,只能在Desktop端使用,Sandbox和Aura不支持使用该工具。 好处:导入时间少,效率高,支持导入数据很大(如超过10M),一次性导入多个CSV文件 缺点:neo4j数据库必须在导入完成后才能使用。

小组分工
个人完成,无具体分工;
实验流程及结果分析
数据处理过程

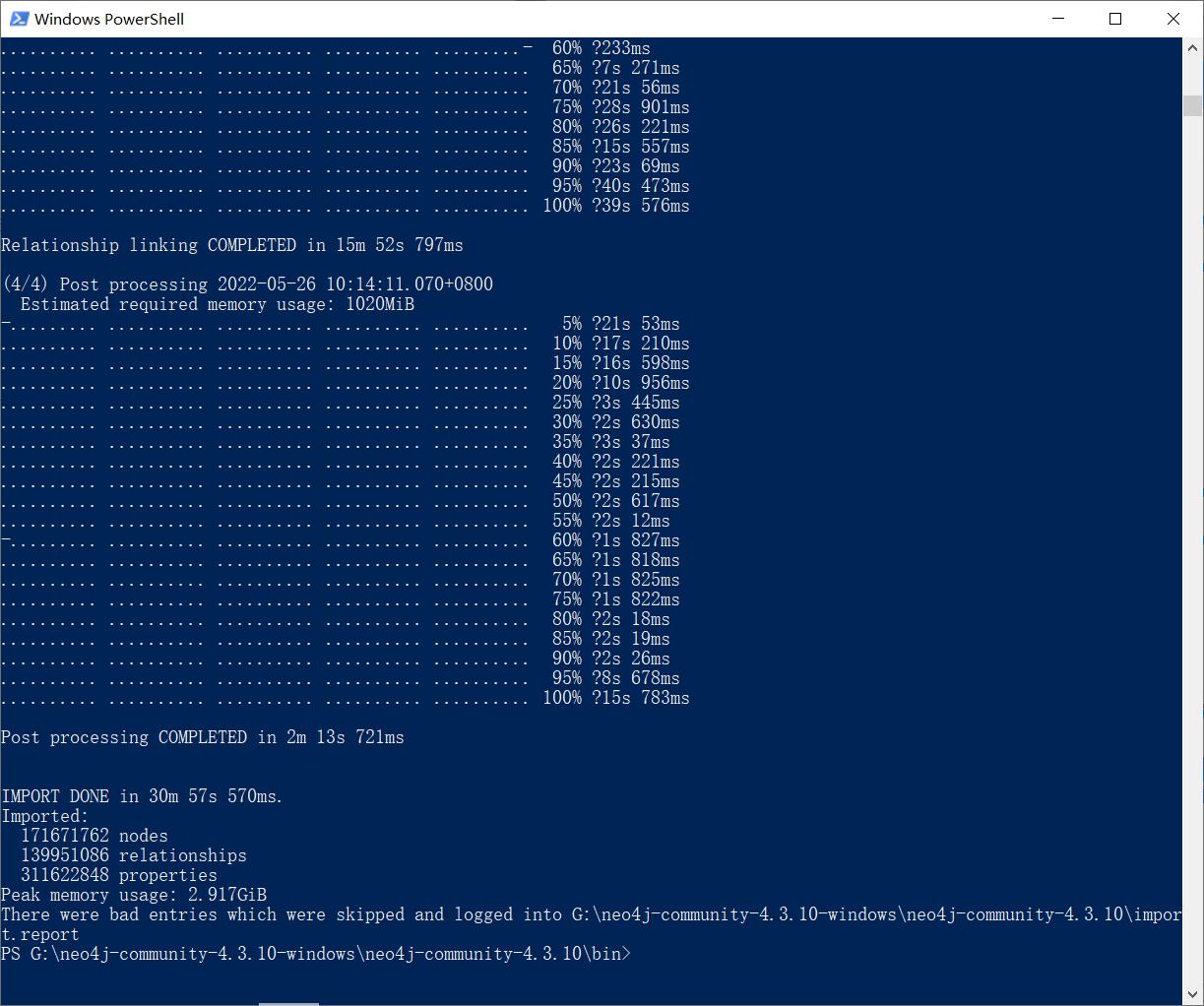
数据导入过程
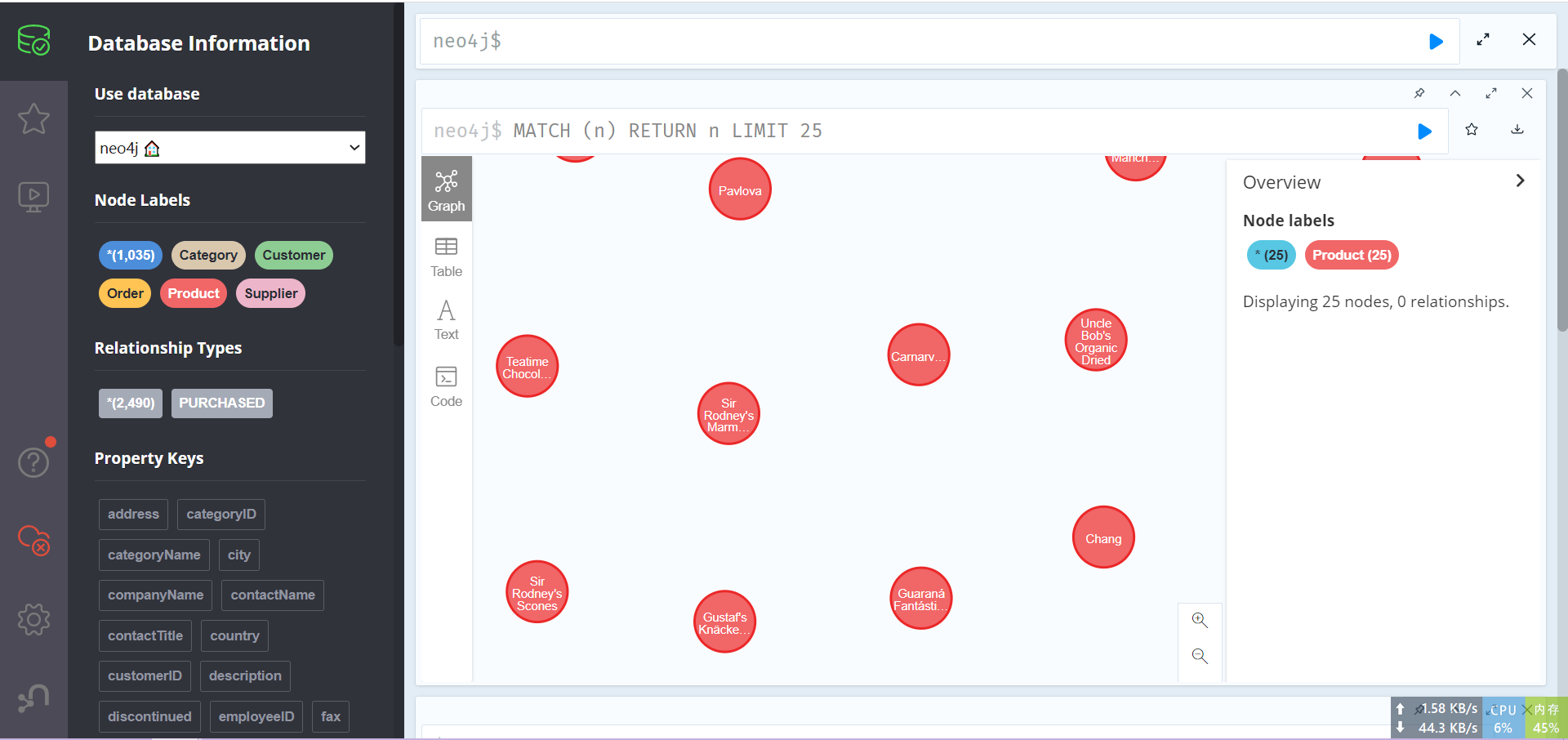
最后结果


遇到的问题与解决方法
由于代码在学习通中已给出,故无大问题出现。
实验总结
通过这次实验,使我了解到了数据清洗的具体过程和步骤,并且对大数据的处理过程有了一个更加清晰的了解,同时,通过数据处理和 Neo4j 数据导入的过程,使我对 Neo4j 更加熟练,收益颇丰。