
PYTHON基础
0.前言
首先对PYTHON进行一个最基本的了解。
1.发展历史
Python的作者,Guido von Rossum,荷兰人。1982年,Guido从阿姆斯特丹大学获得了数学和计算机硕士学位。然而,尽管他算得上是一位数学家,但他更加享受计算机带来的乐趣。用他的话说,尽管拥有数学和计算机双料资质,他总趋向于做计算机相关的工作,并热衷于做任何和编程相关的活儿。
1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了 :类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。 Python语法很多来自C,但又受到ABC语言的强烈影响。来自ABC语言的一些规定直到今天还富有争议,比如强制缩进。 但这些语法规定让Python容易读。另一方面,Python聪明的选择服从一些惯例,特别是C语言的惯例,比如回归等号赋值。
2.优点
简单易学——–Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样,尽管这个英语的要求非常严格!Python的这种伪代码本质是它最大的优点之一。它使你能够专注于解决问题而不是去搞明白语言本身。
解释性————这一点需要一些解释。一个用编译性语言比如C或C++写的程序可以从源文件(即C或C++语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。当你运行你的程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行程序。在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。事实上,由于你不再需要担心如何编译程序,如何确保连接转载正确的库等等,所有这一切使得使用Python更加简单。由于你只需要把你的Python程序拷贝到另外一台计算机上,它就可以工作了,这也使得你的Python程序更加易于移植。
可扩展性————如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
3.缺点
- 运行速度,有速度要求的话,用C++改写关键部分吧。
- 中文资料匮乏(好的python中文资料屈指可数)。托社区的福,有几本优秀的教材已经被翻译了,但入门级教材多,高级内容还是只能看英语版。
5.进行简单的输入输出
按照惯例,先来一个HELLO WORLD,让大家对PYTHON有一个入门的了解。
Str = input("") #输入HELLO WORLD
print(Str) #HELLO WORLD
一.变量类型及运算符
1.变量的定义及使用
在PYTHON中,对变量进行定义时不需要声明变量的数据类型(尽管它存在)。
若定义一个变量,则语句如下:
temp = 10
str = "hello, world"
同时,语句结尾处没有分号 ; ,PYTHON根据分行的机制来确定不同的代码块。
将变量输出,结果如下:
print(temp) #10
print(str) #hello, world
2.变量的类型
在PYTHON中,数据类型大致可分为可变数据类型和不可变数据类型。其中不可变类型有:number(数字), String(字符串), tuple(元组)。
可变数据类型有:list(列表), set(集合), dictionary(字典)。
其中,number 包含:int, long, float, complex。另外注意,在PYTHON2中定义整数时会区分为整型和长整型,当数据超过了整型可以表示的范围之后,会自动转化为长整型。而在PYTHON3中,统一表示为长整型,避免了其的自动转换。
3.数据类型的相互转换
| 函数 | 说明 |
|---|---|
| int(x [,base ]) | 将x转换为一个整数 |
| long(x [,base ]) | 将x转换为一个长整数 |
| float(x ) | 将x转换到一个浮点数 |
| complex(real [,imag ]) | 创建一个复数 |
| str(x ) | 将对象 x 转换为字符串 |
| repr(x ) | 将对象 x 转换为表达式字符串 |
| eval(str ) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s ) | 将序列 s 转换为一个元组 |
| list(s ) | 将序列 s 转换为一个列表 |
| chr(x ) | 将一个整数转换为一个字符 |
| unichr(x ) | 将一个整数转换为Unicode字符 |
| ord(x ) | 将一个字符转换为它的整数值 |
| hex(x ) | 将一个整数转换为一个十六进制字符串 |
| oct(x ) | 将一个整数转换为一个八进制字符串 |
5.基本运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加法 | |
| - | 减法 | |
| / | 除法 | |
| // | 地板除 | |
| % | 取余 | |
| * | 乘法 | |
| ** | 乘方 | |
| = | 比较运算符 | |
| == | 赋值运算符 |
二.字符串
字符串作为PYTHON中一个比较重要的部分,当然要单独拿出来讲解了!
1.字符串的定义
注意:在PYTHON中,并不区分字符及字符串,所以你即可以通过“ ” 双引号来对字符串进行定义,同时也可以用’ ‘ 进行定义。但是要注意上下文统一格式噢!
如:
Str = "hello, world"
Str_1 = 'hello, world'
两者的效果是一模一样的。
2.字符串的拼接
在PYTHON中,字符串可以进行 加法 操作,相当于c语言中的concat()的效果
Str1 = "hello"
Str2 = "world"
Str3 = Str1 + " " + Str3
#hello world
3.字符串的取下标和切片
若有一个变量 Str = “hello”,可以近似理解为它在内存中的存储方式如下:
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| h | e | l | l | o |
故字符串支持取下标和切片操作(可迭代的)
Str = "hello"
print(Str[0]) #h
print(Str[1]) #e
print(Str[0:2:1]) #he
print(Str[0: : 1]) #当对第二个参数隐形表示时,则其代表最后一个位置 + 1,可以取到末尾。 hello
print(Str[: : 1]) #当对第一个参数隐性表示时,则代表第一个位置 hello
print(Str[: : ]) #当对步长进行隐性表示时,则代表步长为1. hello
取下标的操作与对数组的操作相同。
接下来对切片操作进行一定的说明:
切片: [起始点 : 结束点 : 步长]
注意,在选取一定范围内的字符串时,切片遵循的是左开右闭的原则,即从起始点开始,取至结束点前一个位置。
上述代码处后三种方法虽然较为简便,但是会给他人的代码阅读带了极大的困难!!尤其是当其中包含了变量和各种运算时,切记不要如此使用。
同时,也可以对其中的参数进行更改以达到反转字符串的效果,为更快速的能够取到结尾的字符,在PYTHON中还可以如此来理解字符串存储。
| h | e | l | l | o |
|---|---|---|---|---|
| -5 | -4 | -3 | -2 | -1 |
此时若要将字符串进行类似反转的操作,可以将步长改为 -1,则由从左往右变为了从右往左。
示范如下:
Str = "abcde"
print(Str[-2]) #d
print(Str[-1: : -1]) #edcba
print(Str[: : -1]) #edcba 最好不要这样使用!!!
5.字符串的常用函数
| 函数 | 作用 |
|---|---|
| count(“字符”) | 判断字符在字符串中出现的次数 |
| endwith(“x”) | 判断字符串是不是以x结尾,返回布尔值 |
| find(“X”) | 找到X在字符串中出现的最开始的位置,返回下标,不存在则返回-1 |
| format() | 常用于格式化输出,在后面会进一步的讲解 |
| isdigit() | 判断是否为整数,返回布尔值 |
| isupper() | 判断是否为大写,返回布尔值(相同的isxxx() 函数还有很多个,不再进行介绍) |
| lower() | 将字符串全部转化为小写,往往会在对字符串进行统一处理时使用 |
| upper() | 将字符串全部转化为大写 |
| strip(“x”) | 去掉字符串两侧的字符x |
| lstrip(“X”) | 去掉字符串左侧的字符X,简记:left strip |
| rstrip(“X”) | 去掉字符串右侧的字符X,简记:right strip |
| split(“X”) | 将字符串按照字符X进行划分,各个部分为列表中的单个元素(返回一个列表) |
| swapcase() | 将字符串中的大写转化为小写,小写转化为大写 |
| replace(“x”, “y”,替换个数) | 把字符串中的X转化为Y,替换个数默认为全部(若不写的话) |
三.列表
1.列表的定义
若之前有接触过C或C++,则可以将列表理解为一个功能强大的数组。具体的定义如下:
List = [1, 2, 3, 4, 5]
print(List) #[1, 2, 3, 4, 5]
在python中,对列表定义通过 [ ] 方括号来进行。一个列表中数据的类型不必相同,即一个列表中可以同时存储多种类型的数据。
二维列表的定义较为麻烦,可以将其理解为嵌套的一位列表。即一个列表的元素是一个列表,具体的示范如下:
List = [1, 2,[1, 2]]
print(List) #[1, 2,[1, 2]]
print(List[1]) #2
print(List[2]) #[1, 2]
print(List[2][1]) #2
按照这种定义,还会存在三维列表,四维………………等。但实属没有必要,因为二维列表的操作已经略显繁琐,对数组下标较为熟悉的人可以直接通过一维列表来进行类似于二维的操作。
2.列表的拼接
非常不可思议的是,列表竟然可以进行拼接。如下:
List1 = [1, 2]
List2 = [3, 4]
List = List1 + List2
print(List) #[1, 2, 3, 4]
首先需要清楚的是,在定义列表的时候并没有规定列表的大小。即PYTHON中的列表的大小会根据你存入数据的增多而动态的变大,其中涉及了一种叫做分摊的处理方式,感兴趣的同学可以查一查。
3.列表的取下标和切片
很显然,列表是可迭代的,因此支持取下标和切片操作,具体的过程不再进行演示。
下面给出一个有趣的点,具体的原因在后面会进行讲解
List = [1, 2, 3, 4, 5]
other_list = List[::1]
print(id(other_list)) #2249860862984
print(id(List)) #2249860862472
List2 = List
print(id(List2)) #2249860862472
有的同学可能会产生疑惑了,id是什么呢?不要着急,往后面再看看。
5.列表的常用函数
| append() | 向列表的尾处添加一个元素 |
|---|---|
| .insert(index,”x”) | 向列表中下标为index处添加一个元素 |
| remove(“x”) | 删除列表中第一次出现的元素x(若多个则只会删除一个) |
| pop(index) | 删除列表中下标为index的元素 |
| index(“X”) | 返回X在列表中的下标(不存在则会抛出ValueError) |
| count(“X”) | 统计X在列表中的出现次数并返回 |
| reverse() | 对列表进行翻转 |
| clear() | 清空列表 |
| copy() | 浅复制 |
| copy.copy(列表) | 浅复制 |
| copy.deepcopy(列表) | 深复制 |
6.列表的赋值
若想弄明白这个内容,首先需要清楚几点东西:
1.在PYTHON中一切都是对象。这句话是什么意思呢?
对象具有几个特征:id, type, value。id可以理解为每个变量所独有的编号,type为数据类型,value则为数值。
2.可以联想JAVA中或C++中的赋值运算;普通的变量是值的传递,而对象之间的则是地址的传递,通过下面的代码来进行演示:
a = 10
b = 10.0
print(id(a)) #140703169212976
print(id(b)) #2436298180208
print(a == b) #True
可以看到,虽然a 和 b 的值 相同,但是两者的id 并不相同。
a = 10
b = a
print(id(a)) #140703575994928
print(id(b)) #140703575994928
当用 = 将 变量a 和 b 相连时,可以发现两者的 id 相同。
看一下官方对于id()的解释:
def id(*args, **kwargs): # real signature unknown
"""
Return the identity of an object.
This is guaranteed to be unique among simultaneously existing objects.
(CPython uses the object's memory address.)
"""
pass
那么在python中的 = 究竟是怎么回事呢?
a = 10, 相当于创建了一个 值为10 的对象,然后变量a 引用(指针指向)这个对象。

b = a,同理,创建了一个变量b,然后b 引用 a 。
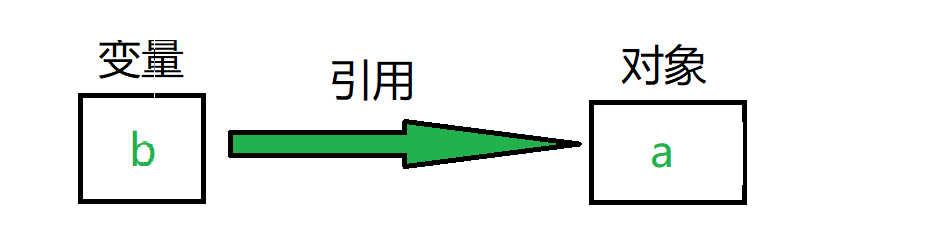
但此处的引用,和地址传递其实有所不同。
主要根据对象是否为可变对象来进行区分。通过以下代码进行解释:
a = 10
b = a
b = 11
print(a) #10
List_a = [1, 2, 3, 4, 5]
List_b = List_a
List_b.pop(1)
print(List_a) #[1, 3, 4, 5]
大家是否稍微有一点理解了呢?int类型为不可变对象,b = 11实际是将b的引用对象从10 更换为11,相当于此时的b已经不是原来的b了。(误)
列表为可变对象类型,当List_b对列表进行修改时,其所引用的对象也会发生变化。但在通过下标操作时又会有所不同,具体如下:
List_a = [1, 2, 3, 4, 5]
List_b = List_a
List_b[2] = 100
print(List_b) #[1, 2, 100, 4, 5]
print(List_a) #[1, 2, 100, 4, 5]
List_a = [1, 2, 3, 4, 5]
List_b = List_a[::]
List_b[2] = 100
print(List_b) #[1, 2, 100, 4, 5]
print(List_a) #[1, 2, 3, 4, 5]
看到这里大家可能就疑惑了,这是为啥呢?
List_b = List_a[: :]相当于先通过[: :]复制了一个列表值为List_a的一个对象,然后再定义一个变量List_b使其引用这个复制出来的对象。
此时生成的对象是一个完全独立的对象(也叫做深复制),与最开始的List_a已经没有关系了。
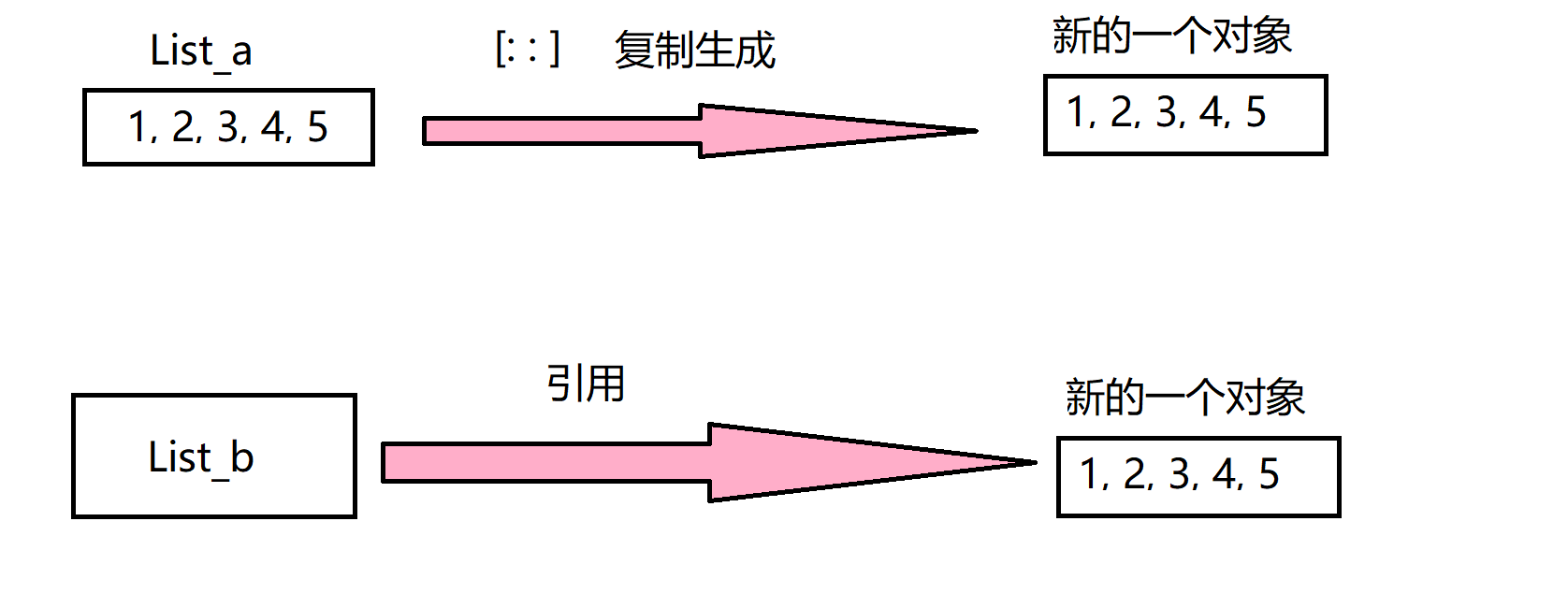
那么,有深复制就有浅复制,来看一下官方给出来的解释:
copy.copy(x)
返回 x 的浅层复制。
-
copy.deepcopy(x[, memo])返回 x 的深层复制。
-
exception
copy.Error针对模块特定错误引发。
浅层与深层复制的区别仅与复合对象(即包含列表或类的实例等其他对象的对象)相关:
- 浅层复制 构造一个新的复合对象,然后(在尽可能的范围内)将原始对象中找到的对象的 引用 插入其中。
- 深层复制 构造一个新的复合对象,然后,递归地将在原始对象里找到的对象的 副本 插入其中。
深度复制操作通常存在两个问题, 而浅层复制操作并不存在这些问题:
- 递归对象 (直接或间接包含对自身引用的复合对象) 可能会导致递归循环。
- 由于深层复制会复制所有内容,因此可能会过多复制(例如本应该在副本之间共享的数据)。
deepcopy() 函数用以下方式避免了这些问题:
- 保留在当前复制过程中已复制的对象的 “备忘录” (
memo) 字典;以及 - 允许用户定义的类重载复制操作或复制的组件集合。
该模块不复制模块、方法、栈追踪(stack trace)、栈帧(stack frame)、文件、套接字、窗口、数组以及任何类似的类型。它通过不改变地返回原始对象来(浅层或深层地)“复制”函数和类;这与 pickle 模块处理这类问题的方式是相似的。
制作字典的浅层复制可以使用 dict.copy() 方法,而制作列表的浅层复制可以通过赋值整个列表的切片完成,例如,copied_list = original_list[:]。
类可以使用与控制序列化(pickling)操作相同的接口来控制复制操作,关于这些方法的描述信息请参考 pickle 模块。实际上,copy 模块使用的正是从 copyreg 模块中注册的 pickle 函数。
想要给一个类定义它自己的拷贝操作实现,可以通过定义特殊方法 __copy__() 和 __deepcopy__()。 调用前者以实现浅层拷贝操作,该方法不用传入额外参数。 调用后者以实现深层拷贝操作;它应传入一个参数即 memo 字典。 如果 __deepcopy__() 实现需要创建一个组件的深层拷贝,它应当调用 deepcopy() 函数并以该组件作为第一个参数,而将 memo 字典作为第二个参数。
说了这么多,大家肯定没看懂是吧,在后面会进一步地对这部分内容进行详细的描述,此处大家只需要有个了解即可。
五.元组
1.元组的定义
首先对元组进行一个概述,元组和列表其实十分相似,但是有一个十分关键的不同,即元组是不可变的。
元组的定义通过 ( )圆括号来完成定义。
Tuple = (1, 2, 3, 4)
print(Tuple) #(1, 2, 3, 4)
这个地方需要注意一下,当元组中只存在一个元素时,需要在这个元素后加一个 , 逗号
Tuple = (1)
print(type(Tuple)) #<class 'int'>
Tuple = (1,)
print(type(Tuple)) #<class 'tuple'>
2.元组的常用函数
由于元组的使用并不是很频繁,故只介绍部分几个函数。
| index(“内容”) | 通过内容找到下标并返回 |
|---|---|
| count(“X”) | 统计元组中X的出现次数,不存在则返回0 |
| _ _ getitems_ _ () | 返回下标(类似的方法为大部分容器类所共有,List,Tuple,Set等) |
六.字典
1.字典的定义和基本操作
在讲述字典的定义之前,大家可以联想一下我们现实中的字典,字典可以根据部首或者是拼音来查询对应的字在这本字典里面的哪一页。此时,部首 + 偏旁(或者是拼音)就与这个字形成了一种对应关系(且是一种一 一对应的关系)
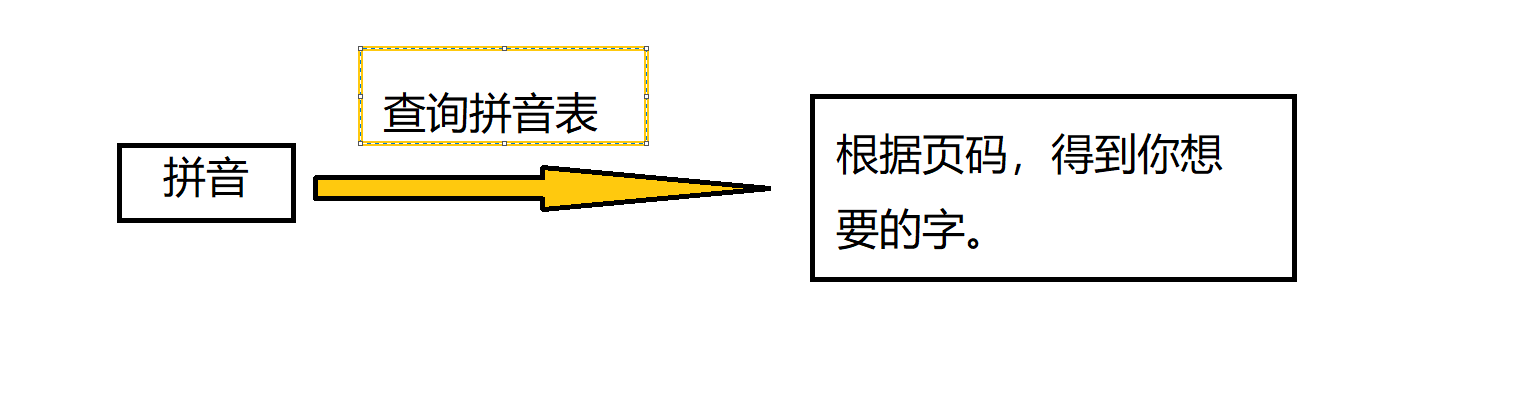 那么在PYTHON中,字典相当于是整个容器, 你可以根据拼音(在PYTHON中称为 KEY)来查询,获得你想要的字(在PYTHON中称为 VALUE)
那么在PYTHON中,字典相当于是整个容器, 你可以根据拼音(在PYTHON中称为 KEY)来查询,获得你想要的字(在PYTHON中称为 VALUE)
字典的定义通过 { } 大括号来完成。由于字典的这种一 一对应的性质,使得字典的应用范围较大,凡是设计这种对应关系的处理时均可以使用字典来进行处理。如学号与学生姓名。
Dict = {"hao" : "好", "ni" : "你"}
print(Dict) #{'hao': '好', 'ni': '你'}
字典作为一个可迭代对象,同样也满足取下标操作,但其取下标的基准基于其 KEY 的值,取出来的是对应的 VALUE 值
Dict = {"hao" : "好", "ni" : "你"}
print(Dict["ni"]) #你
print(Dict["hao"]) #好
注意事项:1.字典的值可以重复而键则不能重复,否则无法确定一对一的关系了。
2.可以将字典中存储的数据理解为一对一对的键值对,即一个键和一个值构成一个键值对,字典由很多的键值对组成。
2.字典的常用方法
| keys() | 返回一个集合(可迭代),其中包含了字典的键 |
|---|---|
| values() | 返回一个集合(可迭代),其中包含了字典的值 |
| setdefault(key, value) | 设置新值,若 key 的值存在则不替换 |
| items() | 返回一个集合,其中的每个元素为字典中的一个键值对 |
| get(“key”) | 返回字典中 key 对应的 value ,若不存在不会出错 |
| popitem() | 随机删除字典中的一个键值对 |
3.字典的遍历
字典的遍历有许多种方式,在下面会一 一介绍一下,当然,肯定有一个是最推荐大家去使用的!
第一种方式最为推荐大家使用,此处的 i 获取的是字典里的键, 再通过取下标操作即可获得对应的值
Dict = {"da" : "大", "jia" : "家", "hao" : "好"}
for i in Dict:
print(i, Dict[i])
"""
da 大
jia 家
hao 好
"""
通过items()函数返回一个键值对来进行遍历:
Dict = {"da" : "大", "jia" : "家", "hao" : "好"}
for k, v in Dict.items():
print(k, v)
"""
da 大
jia 家
hao 好
"""
通过keys()函数返回由键组成的集合来进行遍历:
Dict = {"da" : "大", "jia" : "家", "hao" : "好"}
for k in Dict.keys():
print(k, Dict[k])
"""
da 大
jia 家
hao 好
"""
当然了,由于字典是可迭代的,当然可以使用迭代器来进行遍历:
Dict = {"da" : "大", "jia" : "家", "hao" : "好"}
Iterator = Dict.__iter__()
while True:
try:
key = Iterator.__next__()
print(key, Dict[key])
except StopIteration:
break
"""
da 大
jia 家
hao 好
"""
此处涉及了python中的异常处理,会在后面和大家详细的讲解噢!